Be honest — how often do you use a neural network like ChatGPT? Chances are, you don’t even think twice about it anymore. It has become second nature, almost like running on autopilot.
Planning a vacation? Just ask the chat to map out the perfect route. Drafting a business email for your partners? Let your virtual assistant handle the heavy lifting. From brainstorming ideas to summarizing documents, neural networks have quietly woven themselves into our daily routines, both working and personal.
Machine learning and its algorithms lie at the heart of these assistants that you most probably use on a daily basis. In today’s article, let’s explore the subarea of ML models, with a special focus on language models. What distinguishes large models from small ones? Can the principle “the bigger — the better” also be applied to language models?
Let’s compare SLM vs LLM, and explore which model size delivers the most value — depending on your goals, data, and task specifics.
- Language model size classification
- Why multiple SLMs might work better than one LLM
- Techniques for transforming an LLM into an SLM
- Training intricacies of SLMs and LLMs
- Advantages of target-specific small models
- Classification methods for SLMs
- Usage costs of SLMs and LLMs
- How to select an appropriate model size
- Conclusion
A Continuum: When a Small Language Model Becomes Big
The first obvious question when it comes to language models and the difference between LLM and SLM is: what qualifies as “small” and what counts as “large”? There are no universally accepted parameters to define this clear-cut boundary. While AI model size is often measured by the number of parameters, the boundaries between small, medium, and large exist on a continuum rather than as absolute categories.
A common but approximate classification looks like this:
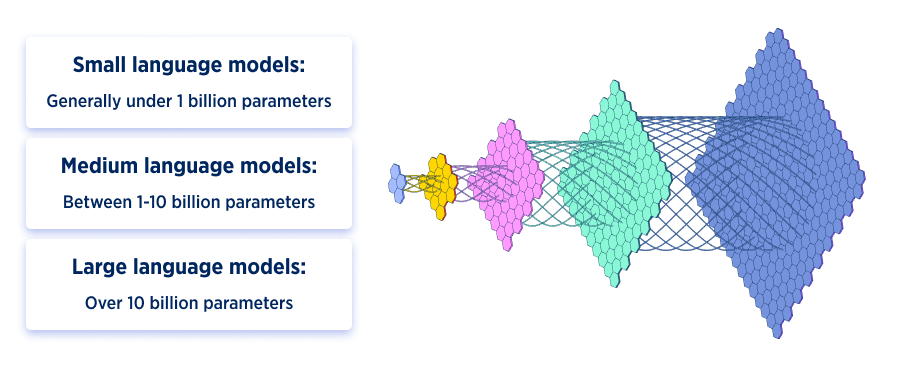
However, these boundaries can shift as technology advances, and different researchers or organizations may use different thresholds.
The term “large language model” has become more widespread and general-purpose — mostly because it entered the scene first. Originally, the focus in artificial intelligence was on natural language processing (NLP), which involved understanding and analyzing human language. It wasn’t until later that models evolved to not only interpret language but also generate coherent phrases and sentences.
The specifics of such models lay in the architecture, which was quite complex and sophisticated. While cumbersome, this design enabled them to deliver exceptional accuracy and high-quality responses.

GenAI for Business
Watch our webinar to uncover how to integrate GenAI for improved productivity and decisions.
With all their virtues, large language models came with a major drawback — they required immense computational resources, making them costly to maintain and scale. This challenge sparked the need to optimize performance and reduce resource consumption, enabling these models to run on more affordable and less powerful hardware. That’s how small language models entered the scene.
Beyond parameter count, LLMs and SLMs differ in their intended usage. Large language models are typically designed to handle a wide variety of tasks across different domains, while small ones are usually optimized for specific objectives or narrow use cases.
One Large Model Outperforms Multiple Small Ones — Fact or Fiction?
Large language models are undoubtedly more comprehensive and capable of handling a broader range of tasks compared to small ones. But does this mean SLMs can’t compete and are unsuitable for serious applications? Not at all, and here’s why.
Small models can excel at narrowly focused tasks when properly optimized. Let’s take the medical domain as an example:
Imagine we have multiple specialized models focused on different medical subfields: one for surgery, another for virology, and so on. Each might have 1-3 billion parameters but is extensively trained on domain-specific data. This specialization can yield responses that are more accurate than those from a general-purpose LLM with hundreds of billions of parameters, especially for technical questions within that domain.
But how do we ensure requests are routed to the correct specialized model? This is where a small language model can serve as an effective classifier, analyzing the incoming query and directing it to the most appropriate specialized model.
Real-World Examples of Specialized SLMs

To support the claim that SLMs can excel in targeted tasks, let’s look at several specialized small models that have shown remarkable performance within their respective domains:
PubMedBERT (110M parameters): Fine-tuned specifically on biomedical literature, this model outperforms much larger general models on medical entity recognition and relation extraction tasks.
LegalBERT (340M parameters): Specialized for legal text analysis, it achieves higher accuracy on contract analysis and legal case classification than general-purpose models several times its size.
FinBERT (110M parameters): Optimized for financial sentiment analysis and outperforms larger models in detecting subtle sentiment shifts in financial reports.
Notable Small Yet Powerful Models
Let’s also review the selection of recently developed small language models that have demonstrated impressive capabilities:
Mistral 7B (7B parameters): Matches or exceeds the performance of models 2-3x its size on many benchmarks.
Phi-2 (2.7B parameters): Despite its small size, shows remarkable reasoning capabilities and outperforms much larger models on certain coding and reasoning tasks.
FLAN-T5 Small (80M parameters): Excellent for specific classification and generation tasks when fine-tuned.
Gemma 2B (2B parameters): Google’s efficient open model delivering strong performance for its size.
Generally, the working principle of SLMs is akin to the the human brain functions — with its different parts responsible for specific tasks. Vision, hearing, and other sensory or cognitive functions are handled by dedicated areas, meaning the brain doesn’t operate at full capacity for every action.
A similar principle applies to language models. When processing a request, a large model doesn’t activate all its hundreds of billions of parameters. Instead, it selectively engages only the relevant portions likely to contain the answer. This is known as “sparse activation,” and it’s an active area of research in making large models more efficient.
DeepSeek’s approach illustrates this principle well. Their MoE (Mixture of Experts) architecture activates only a small fraction of parameters for each query, reducing computational costs while maintaining high performance. According to benchmark results published by DeepSeek, their 7B MoE model achieved performance comparable to dense models with 2-3x more parameters while using significantly less computational resources for inference.
Techniques for Transforming an LLM Into an SLM
A growing trend in the AI field is the shift from relying on a single LLM to deploying multiple smaller, specialized models. This approach helps reduce resource consumption while improving both response speed and accuracy. Here are several established techniques for effectively downsizing large models:
Layer Pruning

Each language model consists of multiple transformer layers, and reducing their number is one straightforward technique. While this initially decreases the model’s capabilities, performance can be largely restored through subsequent retraining or fine-tuning.
Research by Microsoft Research and Meta AI has shown that transformer models can maintain 80-90% of their original performance while removing 30-40% of their layers, especially when followed by targeted fine-tuning. However, there’s a critical threshold beyond which performance degrades rapidly.
Knowledge Distillation

In this approach, a smaller “student” model learns to mimic the behavior of a larger “teacher” model. Google’s DistilBERT demonstrated that a model with 40% fewer parameters could retain 97% of the larger BERT model’s language understanding capabilities through effective knowledge distillation.
Quantization
This technique reduces the precision of the numbers used to represent the model’s weights. Converting from 32-bit floating-point to 8-bit integers or even lower precision can dramatically reduce memory requirements and increase inference speed with minimal performance loss.
Meta’s LLaMA 2 models maintained over 95% of their original performance when properly quantized to 4-bit precision, reducing their memory footprint by up to 8x.
Weight Pruning

Different from layer pruning, this technique removes individual connections within the neural network that have minimal impact on performance. Research has shown that up to 60% of weights can often be pruned with proper retraining, resulting in much smaller model sizes.
Read about Generative AI Models and Their Types
Model Training Intricacies Explained

The training processes for LLM vs SLM differ in several key aspects:
Traditionally, LLMs are trained on massive, diverse datasets spanning multiple domains and languages. This approach gives them broad knowledge but requires enormous computational resources. For instance, Training GPT-4 was estimated to cost between $50-100 million according to industry analysts.
Unlike training LLMs, the process of training SLMs is significantly less resource-intensive. Several effective approaches have emerged for this purpose — let’s explore them below:
Training from scratch on domain-specific data: When focused on a narrow domain, SLMs can be trained directly on relevant datasets, resulting in highly specialized capabilities.
Distillation from larger models: As mentioned earlier, knowledge distillation allows smaller models to learn from larger ones, capturing much of their capabilities while reducing size.
Fine-tuning pre-trained models: Starting with a moderately-sized pre-trained model and fine-tuning it for specific tasks often provides the best balance of performance and efficiency.
The main challenge with small models is their limited capacity to retain information. When training or fine-tuning an SLM, new knowledge may partially overwrite existing capabilities — a phenomenon known as “catastrophic forgetting.”
This raises an important question: how do you choose the right data to train a language model? Given the constraints of limited memory, it’s essential to carefully curate domain-specific data relevant to your particular project or use case.
In most cases, this involves fine-tuning pre-trained models using your organization’s proprietary datasets. During this process, the original generalized knowledge in the model is partially adapted, allowing it to acquire specialized understanding tailored to your product or use case.
The Advantage of Multiple Specialized Models

While LLMs generally outperform smaller ones in terms of overall capabilities due to their vast memory and extensive knowledge base, this advantage isn’t universal across all applications.
The increasingly relevant field of agentic AI — where multiple specialized AI components work together to accomplish complex tasks — is an area where small language models often demonstrate significant advantages.
Consider this architecture:
One SLM handles database queries
Another processes data analytics
A third generates data visualizations
A fourth performs quality checks and verification
Learn about 6 Types of Data Analysis That Help Decision-Makers
When a user submits a request, it flows through this chain of specialized models, with each handling its specific task before passing results to the next component. The final output combines the expertise of each specialized model into a comprehensive, accurate response.
This approach offers several advantages over using a single large model:
Higher accuracy on domain-specific tasks: Each specialized model focuses exclusively on its area of expertise.
Better resource allocation: Computing resources are directed only where needed for each query.
Improved explainability: The contribution of each component is clearly defined.
Easier updates and maintenance: Individual components can be updated without affecting the entire system.
According to benchmarks from Stanford’s DSPy framework research, routing complex questions through specialized components improved accuracy by 15-20% compared to using a single LLM, while significantly reducing computational costs.
Despite the vast number of parameters a large model may possess, it is often more prone to errors when handling simple, narrowly defined tasks, especially compared to smaller ones that have been fine-tuned for specific functions. The main challenge lies in accurately classifying the incoming task and routing it to the appropriate model capable of resolving it quickly and efficiently.
Correct Request Classification Is Half the Battle
Small language models typically handle the critical classification function in multi-model systems, routing incoming queries to the appropriate specialized model. Several approaches are commonly used:
Keyword-Based Classification

The simplest approach relies on detecting specific keywords or phrases. For example, if the model encounters the word “guitar,” it may assume the request pertains to music and redirect it to a model trained in that domain.
While straightforward to implement, this approach focuses solely on surface-level terms, without considering the broader context of the request. This can lead to misclassification when keywords appear in unexpected contexts.
Semantic/Contextual Analysis

A more sophisticated approach involves analyzing the entire structure and meaning of the request, evaluating its semantic intent rather than just isolated keywords. This enables a more accurate understanding of the user’s intent and ensures that the query is routed to the most suitable model.
While semantic analysis offers greater accuracy, it tends to be more resource- and time-intensive than simple keyword matching.
Hybrid Approaches

Most production systems use a combination of both keyword detection and semantic analysis, adjusting the balance based on the specific requirements and complexity of the application. This provides a good balance between accuracy and efficiency.
Companies like Cohere have reported that their hybrid routing systems achieve 95%+ routing accuracy while adding only 10-30ms of latency to the query processing pipeline.
Cost and Energy Considerations: A Quantitative Comparison
The resource requirements between these types of language models differ dramatically:
Model Size |
Training Cost |
Inference Cost (per 1M tokens) |
Carbon Footprint (training) |
|---|---|---|---|
| Small (< 1B) | $5K-$50K | $0.05-$0.20 | ~10 kg CO₂e |
| Medium (1-10B) | $50K-$1M | $0.20-$1.00 | ~100-1,000 kg CO₂e |
| Large (>10B) | $1M-$100M+ | $1.00-$10.00 | ~10,000-100,000 kg CO₂e |
These figures are approximate and vary based on specific models, hardware configurations, and efficiency optimizations, but they illustrate the dramatic difference in resource requirements.
How to Choose: Decision Framework for Model Selection
When conducting AI model size comparison and deciding between large and small language models for your application, consider these key factors:
Task complexity and domain breadth:
For broad, general knowledge tasks → Larger models
For narrow, specialized tasks → Smaller, fine-tuned models
Available computational resources:
Limited compute budget → Smaller or quantized models
Abundant compute resources → Larger models possible
Latency requirements:
Need for real-time responses → Smaller models
Batch processing or non-time-sensitive tasks → Larger models viable
Accuracy requirements:
Mission-critical applications requiring maximum accuracy → Larger models or specialized small models
Applications where approximate answers are acceptable → Smaller models
Deployment environment:
Edge devices (smartphones, IoT) → Highly optimized small models
Cloud environments → Either size, depending on other factors
Final Words
Comparing large language models vs small language models, we must understand that they each come with their own advantages and limitations. The right choice ultimately depends on your specific use case, resource constraints, and performance requirements.
If resource and energy consumption aren’t a concern and you need broad capabilities, LLMs with billions of parameters may be appropriate. However, for many specific applications, specialized smaller models can deliver superior results with dramatically lower costs and environmental impact.
The future likely belongs not to a single approach but to intelligent combinations of models — using the right-sized tool for each specific task. As technologies like model compression, quantization, and efficient architectures continue to advance, we can expect the performance gap between large and small models to narrow further.
Are you still unsure which type of ML model is the right fit for your needs? Our team of machine learning experts can help evaluate your use case and design the most efficient solution tailored to your specific goals and constraints!
Get the conversation started!
About the author